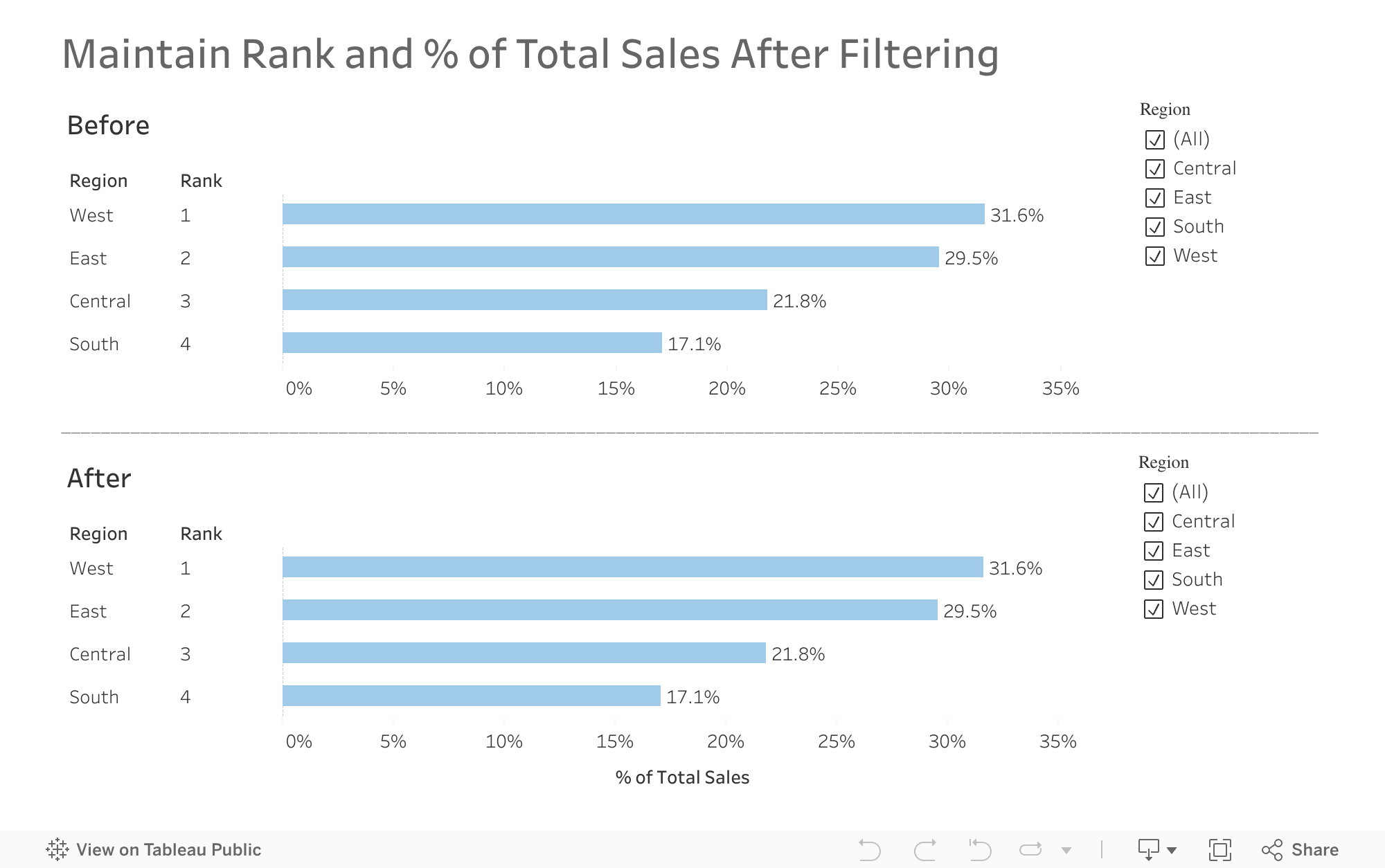
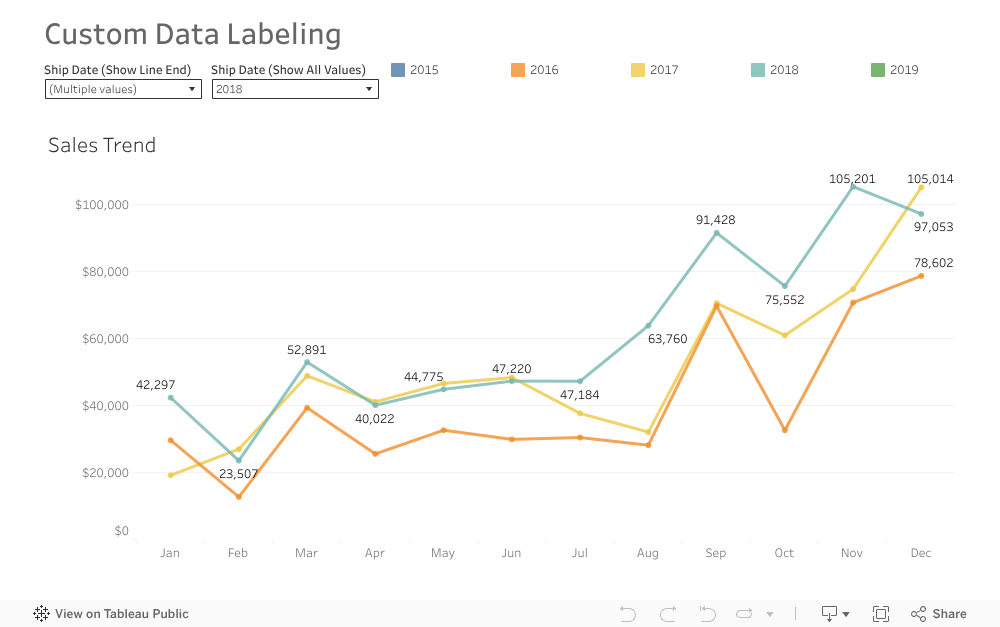
ServiceNow Supplier Lifecyle Operations (SLO) automates and simplifies interactions and collaboration across the end-to-end relationship with a supplier. This allows for more seamless purchasing, primary data management, and performance management, across work teams and allows procurement and suppler managers to refocus on more strategic priorities. Built on the Now Platform, Supplier Lifecycle Operations integrates seamlessly with existing ERP and procurement technologies to deliver faster time-to-value, while streamlining fulfillment and reducing the potential for errors or delays.
Please visit ServiceNow, the AI platform for business transformation, to explore more about its portfolio of cost-saving products, now supercharged with AI agents.